
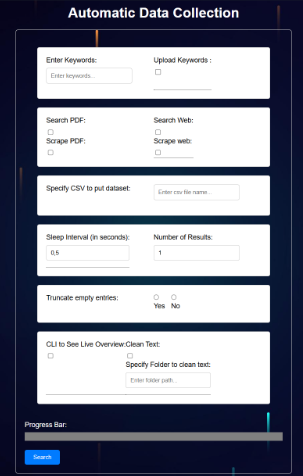
Datasets are an important aspect of training large language models. Our goal was to create a dataset which could be used for training a LLM, specifically about mortgages. We wanted to create the dataset using tools to collect the necessary data and make it ready to be fine-tuned. Our client also wanted to be able to use these tools later for further creating the chatbot. We made a dashboard, where a user can collect (specific) data from the internet or PDFs. The user can specify their preference for obtaining the desired data. This dashboard enhances the process of creating a dataset for a LLM by collecting data based on the specific keywords. Our project scope primarily focused on delivering a high quality dataset, with the tools we made for the data retrieval. Furthermore, we provide the tool with basic data cleaning on the dataset which could then be further preprocessed by the user.
Our client for this project was Stater N.V., a Dutch mortgage service provider. The IT department of this company is currently working on creating a chatbot. They want to do this so that clients or employees of the company can ask questions about mortgages more easily. For the first few weeks we had weekly meetings and after we made some progress with the project, we switched over to bi-weekly meetings. Our main contact points were Roy Rops and Jens van Holland. Roy is the Lead Data Lab and Jens is a data scientist for Stater. During these meetings we discussed our progress on the project, the requirements for the project, and also problems we ran into, where Roy and Jens would provide valuable feedback that helped us work on the project.
Our team, Code Cookers, consists of 7 team members coming from a variety of studies, namely, Computer Science, Data Science and Artificial Intelligence, and Bioinformatics. Using Scrum, we were able to successfully divide the tasks between all team members. We held weekly meetings within the team to discuss our progress and ensure every member had a task to work on. The work was mostly split up into frontend and backend. We formed teams where 3 people would work on the backend and 4 members worked on the frontend of the dashboard.