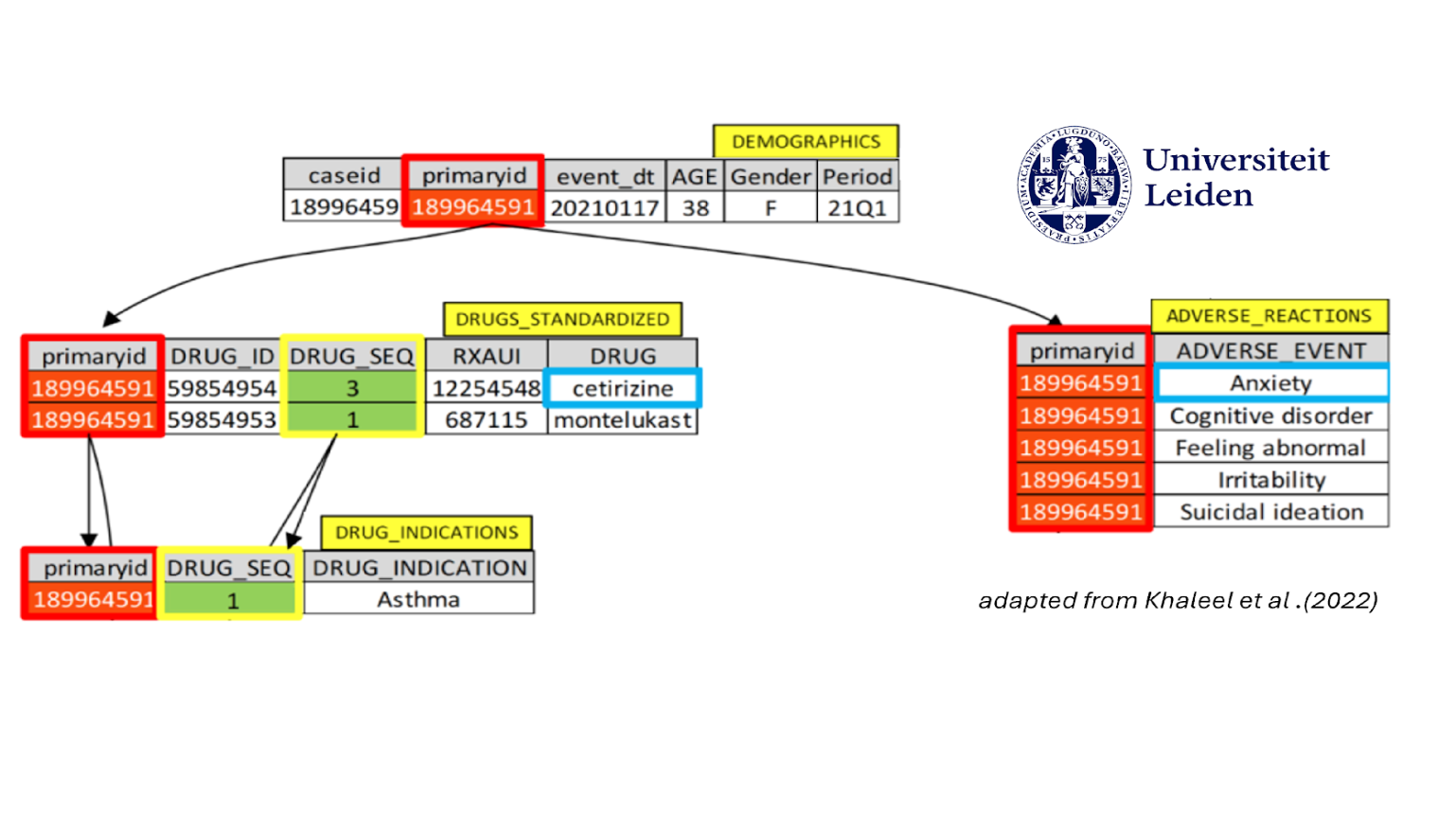
FAERS Database Pipeline

The FAERS Database SQL Pipeline, developed for the Leiden Academic Centre for Drug Research (LACDR), automates the previously manual and complex process of updating the FDA Adverse Event Reporting System (FAERS) database. This database contains reports of adverse effects of several drugs. Previous attempts were error-prone and challenging for staff. The delivered pipeline uses a single Python entrypoint script to execute 1-3 commands, automating data retrieval, deduplication, and normalization with RxNorm and IDD, while JSON configurations and a CI/CD pipeline with SQLFluff, ShellCheck, pgTAP, and Bats ensure flexibility and code quality; it runs on PostgreSQL, and includes comprehensive documentation for maintainability. This solution saves time, minimizes errors, and provides a reliable, scalable product that supports LACDR's research and analyses, earning client satisfaction for its future development potential.
The client, Laura Zwep, an assistant professor at LACDR, specializes in drug research and statistics, not computer science, and oversees a FAERS database used by students for statistical analyses. Communication with Laura was effective, conducted through biweekly sprint review meetings held in person at LACDR or via Teams. She provided clear feedback on requirements, server access, and usability needs, expressing satisfaction with the team's ability to work and troubleshoot independently.
The FAERS Database SQL Pipeline team, consisting of Florian Trosemito, Kai Epprecht, Khayri Mohamad Hafiz, Levi Ari Pronk, Noah Klein, and Xocas Alvarez-Jorge, was led by Xocas as Product Owner, managing client communication, and Noah as Scrum Master, overseeing task delegation. Work was divided by pipeline components, with each team member assigned specific scripts or aspects of the pipeline to manage. We collaborated well, with team members helping each other. The team overcame challenges like LACDR VM access issues, PostgreSQL migration complexities, and Script 2 blockers by migrating to AWS/Google Cloud, improving communication through frequent meetings, and adopting parent-child issue structures. We are most proud of reviving a 3-4-year dormant pipeline, delivering a functional, well-documented Product that met client needs and supports future LACDR research.
Python, SQL, Bash, PostgreSQL, GitHub Actions, SQLFluff, ShellCheck, pgTAP, Bats, Git, AWS, Google Cloud, JSON, CSV, Overleaf, LaTeX, FAERS, RxNorm, IDD, MedDRA, psql, VIM, VS Code, PuTTY, wget